Estimated Reading Time: 9 minutes
Yes, zvelo has a unique approach to categorizing web content at the domain and full path level. The underlying methodology and infrastructure has been a labor of continuous development and improvement over the last twenty years. In this blog, we’ll break that approach down and show how we’re able to achieve the highest levels of coverage and accuracy of all the trafficked websites on the internet.
Before we dive right in, let’s take just a moment to look at the scope and challenges of taming the fast-growing World Wide Web…
A Brave New (Digital) World
In under three decades since its inception, the World Wide Web has grown to a staggering size and become a monument to the collective intelligence of the human race. Arguably, Tim Berners Lee’s brainchild has become one of the most important inventions in the history of the human race—having now connected over 4 billion users worldwide. But along with the convenience, power, and all the advantages of the internet—we’ve created a few (cough) challenges for ourselves.
As reported by Netcraft, in November 2018 the internet is estimated to contain nearly 1.7 billion websites. That number is derived from a sampling of base domains where unique hostnames (not subdomains) and homepage content is found for all sites on an distinct IP address.
But this illustrates the size and scope of the challenge. 1,652,185,816 websites.
Let’s say we gave you the list of all of those websites so that you could review all of the top level websites (hostnames)—NOT INCLUDING individual full path webpages (for which sites like Facebook, CNN, Amazon, Baidu, Wikipedia, and YouTube can have hundreds of thousands or even millions). So, considering that you’re dedicated, well-caffeinated, and a raving lunatic—let’s pretend that you’re capable of reviewing the list from start to finish at a pace of 10 websites per second. Without any breaks (i.e. sleep, eating, bathroom breaks, sneezing, resting your eyes, etc.) it would take you approximately 5.4 years (or 1,971 days) to complete that list. Not bad!
But wait…Based on the trajectory of growth, by the time you finished reviewing that list the internet would will have doubled in size again.
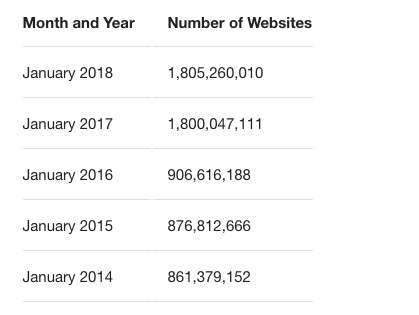
Source: Tek Eye (chart/image) and Netcraft
So even if we could keep that list up to date and accurate, that’s over a decade worth of time just to review existing sites. In terms of the scope of total web content, there are many many times more individual webpages, files, images, videos, posts, articles, etc.
Adding to the complexity, the web landscape is continuously changing—particularly those websites that are malicious and objectionable in nature. And cybercriminals grow more sophisticated by the year—deploying sites with increasingly short shelf-lives that help them control botnets (command and control), spread ransomware, conduct phishing attacks, and more. But it’s not just malicious websites that change frequently. On a regular basis, millions of domain names and websites are bought and sold, and millions of new webpages pop up with new content, images, and executables.
You get the idea. Categorizing the internet in its entirety—effectively and accurately—is going to require forward thinking and next-generation technologies just to keep up with the increasing pace.
Some Traditional Approaches
Businesses, platforms, and cybersecurity companies have employed a number of tactics to combat the mounting security threats, fake news, bots, and other problems that threaten to destabilize our social mores and our trust in governing institutions. We’ll take a quick look at just a few of these trends to understand the challenges.
“Just Add More Analysts”
There are a number of problems with this approach. It is prohibitively expensive to approach this as a “humans vs. machines” challenge. Humans are great at a lot of very complex tasks that machines aren’t—but when it comes to throughput and repetitive tasks—human workers are no match for a computer. And advancements in AI/ML are only increasing that gap. For the good guys and cyber criminals, alike.
Additionally with this approach, as it’s been seen in numerous studies, it is difficult to achieve any level of consistency in categorization results unless each analyst could be preprogrammed with a defined set of beliefs, values, and biases. Which cultures, styles of governance, and religions should the analysts base their assessments on?
“My Blocklist is Bigger Than Your Blocklist.”
Some of our competitors like to boast that they have the [insert superlative here] solution and protection because they have an extensive list IPs and sources that they’ve accumulated over the years. Once upon a time, that was an effective way to block network connections to malicious sources—but that’s rapidly becoming obsolete.
The reality is that the majority of malicious sites have lifespans of days and weeks, rather than years. This means that malicious IPs and websites collected over years of malicious detection efforts are no longer active or infected—and unless your blocklist is being actively/continuously scanned, pruned, and managed—it’s just bloat. Achieving a high level of detection coverage—and therefore protection—requires an advanced system of gathering active and “fresh” URLs (we have a crowd-sourcing network for instance) and maintaining that list through revisits and analysis of known malicious classifications to understand when they are cleaned or no longer a threat.
Achieving high accuracy is one thing. Achieving up to the minute—or up to the second—accuracy is another level entirely.
“But We Actively Scan The Entire Internet”
Some—including search engines (i.e. Google, Bing, Baidu, etc.), those mentioned at the beginning of this blog, and others—use web crawlers and other methods to “actively” scan parts of the internet.
In the case of search engines, this is to identify websites and information for the purpose of providing search tools. For others, it may be to gather information for statistics. But this approach is also by bad actors to to skim email addresses, look for security vulnerabilities, find botnet targets, and propagate malicious code.
Theoretically, a host of web crawlers and proxies COULD be used to actively crawl every webpage, file, and link found—but without proper agreements (and there would have to be A LOT) in place this would violate even the most benign of website terms and conditions. This also isn’t helpful for identifying threats and compromises behind firewalls—or on the Deep Web.
In certain situations, targeted “active-scanning’ techniques are helpful for forensics and malicious detection—but for a number of reasons this is ill-suited and inefficient for the purposes of combing the entire internet. In the end, many of these approaches have some value for specific ends—but they are not the primary driving forces that lead to genuine improvement and next level results in this space.
Coordinated Human + AI Processes for Web Filtering
In our years of experience we’ve found that the highest levels of coverage and accuracy (and therefore, protection) result from a hybrid approach. Our engineers and web analysts have spent the better part of a decade building and optimizing a distributed cloud network with AI models and training datasets that continuously raise the bar on categorization coverage and accuracy for languages worldwide.
There is a long list of methodologies, technologies, and systems that make up the zvelo categorization engine—but to put it simply—our hybrid approach includes the following key strategic elements:
- Human-supervised Machine Learning (HSML)
- A Crowdsourced Network of Endpoints
- Natural Language Processing & Machine Translation
- Static, Behavioral, and Heuristic Analysis for Malicious Detection
Human-supervised Machine Learning for Web Filtering and Malicious Detection
Our AI architects and engineers have built models, microservices, and training datasets that analyze and categorize web content at the IP, domain, and full path level based on a varying number of factors and signals. Between our ongoing partnerships with OEMs, regulatory bodies, and vendors across a range of industries (specifically cybersecurity, ad tech, and high-tech) we collect and leverage network traffic insights, feeds, blocklists, and tools that inform and continuously improve our systems.
Crowdsourcing the Network of Endpoints
For the reasons discussed earlier—zvelo has focused its efforts on OEM partnerships and crowdsourcing to grow our endpoint network and scanning capabilities that inform our categorization systems.
Our OEM partners provide a wide range of services and solutions to a worldwide user base (i.e. “end users”). When an end user visits a website, webpage, article, image, etc. the respective zvelo-powered deployment is queried for that URL/location. When the location exists within the zveloDB, a category value is returned for use within the partner’s integration and the end user continues on with their web experience. If the location does not exist within the database (i.e. is not categorized), the URL/location is submitted to the zvelo network where appropriate processes are executed and webpage elements and content are analyzed/categorized.
At regular intervals, the updated database is distributed back to all of our partner’s deployments. In addition, zvelo’s malicious detection systems continuously revisit newly identified and known malicious sources—which are reanalyzed and and updated or pruned from our master database once a source is deemed safe.
For these “high priority” category changes/updates (i.e. malicious detections, security changes, miscategorizations, objectionable updates), zveloDB Instant Protection (zIP) provide real-time protection by instantly updating deployments around the world.
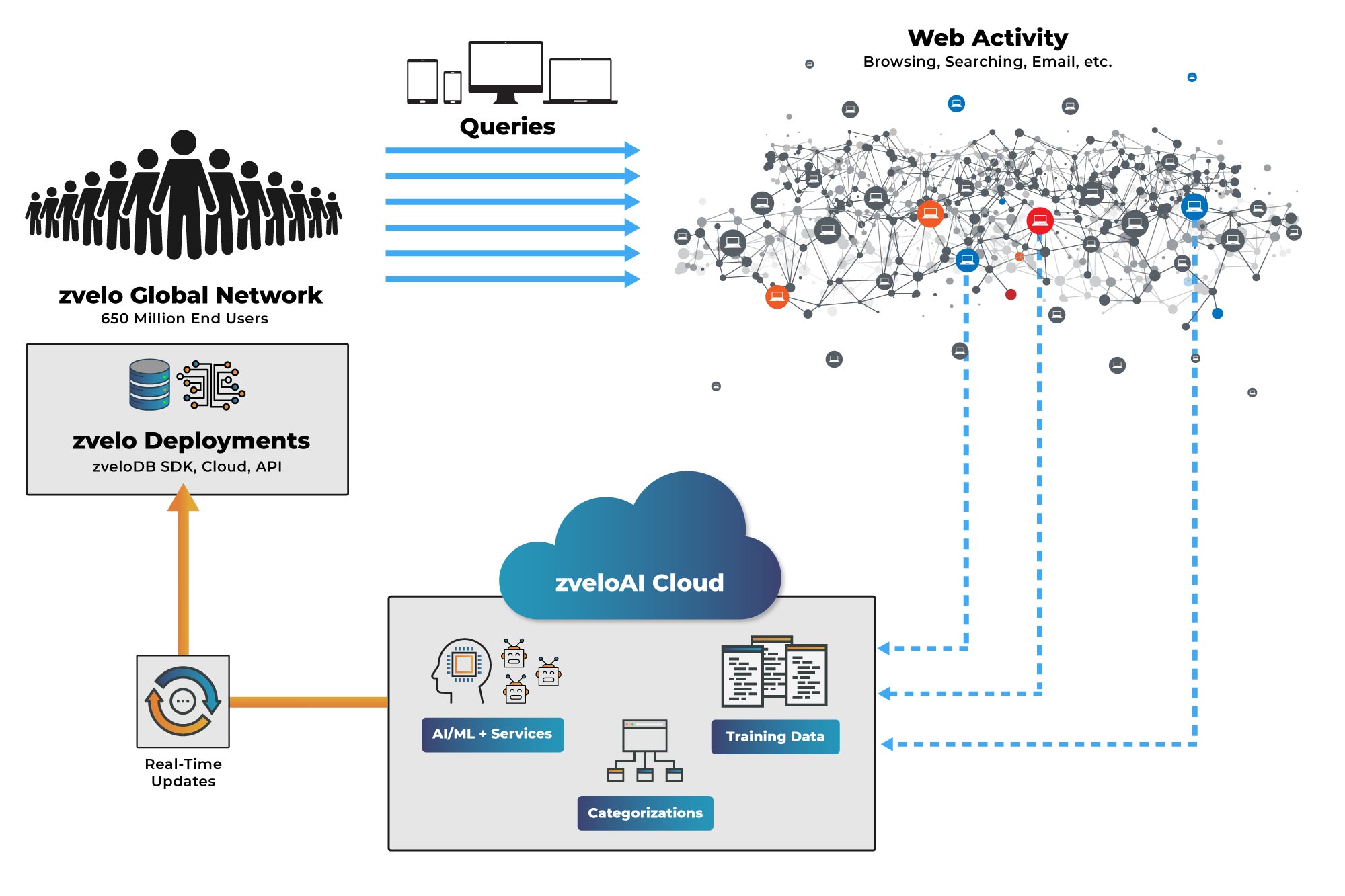
Ultimately, end users benefits from the categorizations and detections from the combined web-browsing patterns and habits of the entire network. In this way, the zveloAI network effectively has over 650 Million endpoints for exploring the internet—encountering and identifying new sites and content—and feeding the categorization engine.
Natural Language Processing & Neural Machine Translation
In our efforts to provide a world-class categorization engine, we’ve in turn had to develop a highly effective translation workflow/engine to support a global end user network and languages worldwide. While English (which has historically made up for the majority of web content worldwide) still accounts for the highest percentage of web content overall—other languages like Chinese, Spanish, Arabic, and others continue to grow and contribute to a larger piece of the total pie.
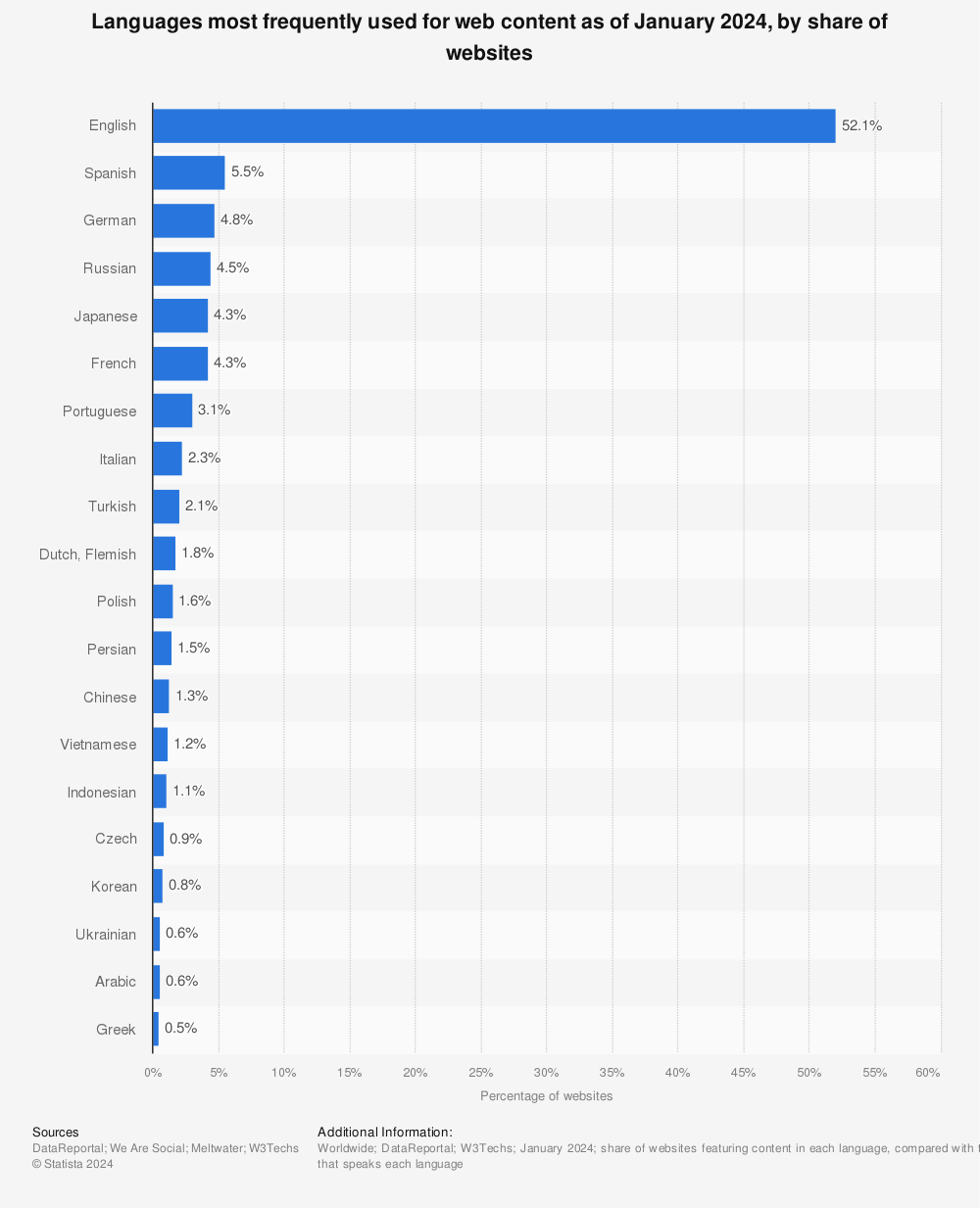
Find more statistics at Statista
We approach translation using a state of the art deep learning system—which is a state of the art machine translation approach. More specifically, using a neural machine translation (NMT) system that is trained on billions of parallel sentences, we translate content from non-English sites and webpages to English before analyzing and categorizing. In this way, the system is multilingual, allowing us pre-process all content, translating it prior to categorization.
The translation system is designed for high throughput and efficiency in order to meet the demand of categorizing URLs gathered by our global network of end users.
Static, Behavioral, and Heuristic Analysis for Malicious Detection
zvelo leverages a variety of static, behavioral, and heuristic methods for malicious detection and analysis (including proxy networks, scanners, algorithms, hands-on “human-powered” forensics, and more) to achieve real-time identification of URLs and IPs associated with viruses, malware, botnets, phishing campaigns, and more. In coordination with our human-supervision feedback loop and machine learning models—this is one of the core advantages.
This is hardly an exhaustive overview, but represents our core pillars for innovation and quality with regards to our categorization engine. Additional important elements in zvelo systems include:
- Additional Revisitation Processes based on URL Category
- Closed Feedback Loop for Continuous Retraining & Improvement
- Ongoing Random Sampling for Quality Assurance and Retraining Efforts
- And more…
Conclusions
With 20 years of experience in cybersecurity and malicious detection—and over a decade building solutions/relationships for and with anti-virus vendors, security providers, and OEM partners in communications, ad tech, and a number of other high-traffic industries—zvelo has built a hybrid approach to categorizing and mapping the internet. The results are industry-leading coverage (over 99.9%) and accuracy (over 99%) across the ActiveWeb and for languages worldwide!
To learn more about how our award-winning zveloDB URL Database and other zvelo solutions can empower and help provide additional protection for your users—contact our technical team!
Or try it for yourself with the zveloLIVE tool at https://tools.zvelo.com.





