Building a Data as a Service Platform for AI – Q&A with a zvelo Engineer
With the recent release of zveloDP™, zvelo’s Data as a Service platform, we thought it was an excellent opportunity to ask some questions about the platform and get some insight into the technology behind the curtain.
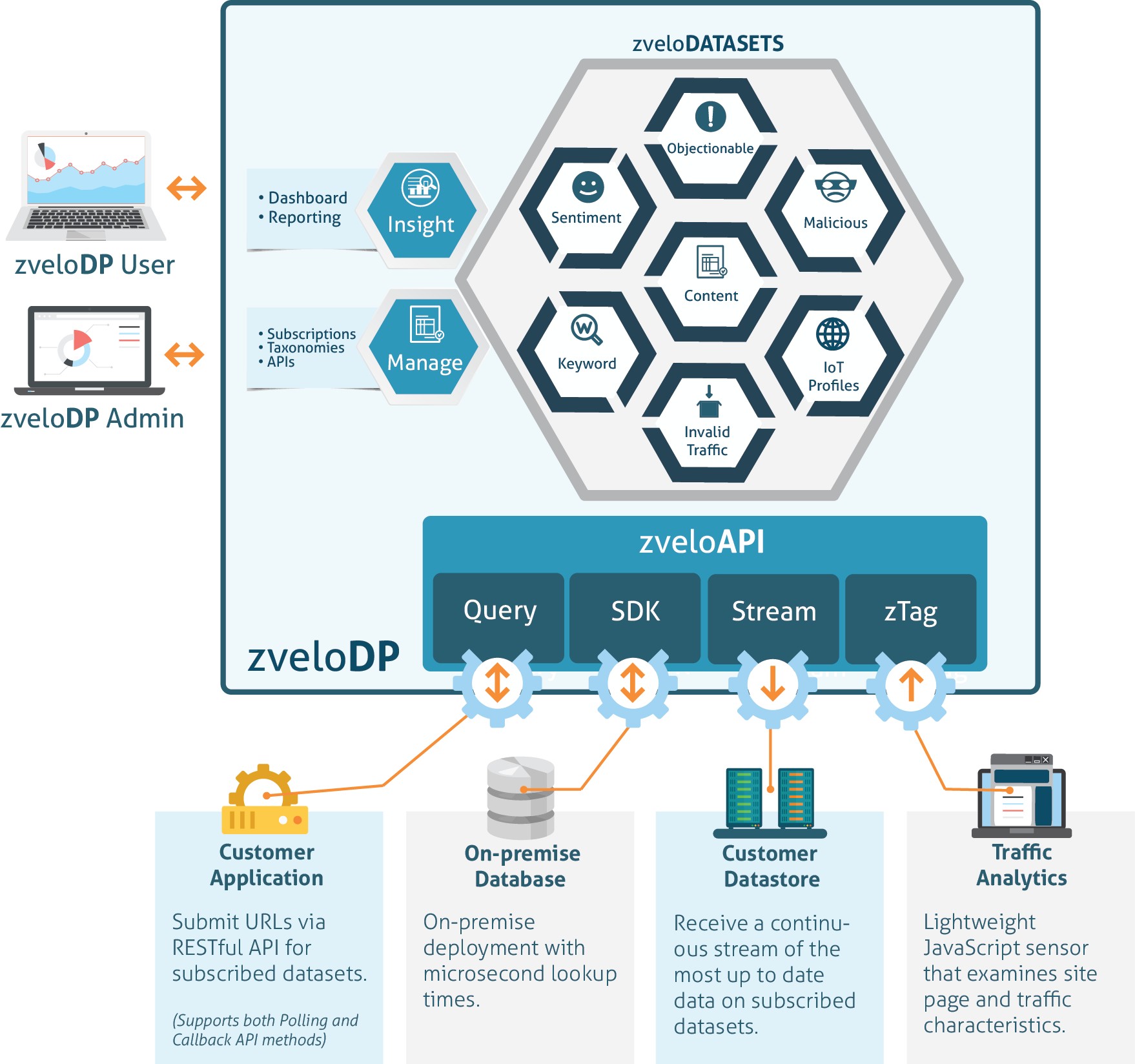
Q: First things first, what is zveloDP?
At its core, the zveloDP is an API to a trained AI that “sees” the internet. This AI makes what it sees available to developers using a Data-as-a-Service approach, which is utilized for a myriad of purposes.
Q: What are some of these “myriad purposes”?
Network Security and Internet Privacy come to mind. The AI can be used to detect malicious bot activity, network intrusions, or as a network firewall to known malicious web locations. It also protects our internet privacy by providing new ways for advertisers to create contextually relevant, targeted ads without user profiling.
Q: How can a network security and categorization AI be used for Ad-Tech?
More than detecting viruses, malicious network activity, or bots, the AI engine is trained to identify and emit substantially more information about an entity on the wider web, either hard or soft. For instance, it will tell you if a site is about travel, or about sailing, or both. It may not seem obvious at first, but this is desperately needed by the advertising industry to ensure ad dollars are spent wisely, and in a way that enables internet privacy.
The infrastructure comprising the Internet today is primarily funded by advertisements. The explosion of “Ad-tech” in recent years is a moniker referring to the use of advanced advertisement-specific technologies to make this growing marketplace useful for both advertisers and their intended audience. However, the general trend has been to gather information about an individual, create a very detailed browsing profile across their devices, and then use these data to target ads for higher click-throughs and conversions. However, this approach necessitates compromises and introduces risks.
As a company, we are very interested in internet privacy. Our AI opens the possibility of providing contextual, highly targeted advertisements without requiring personal information gathered from user tracking. It also works for the increasing number of internet users who browse fully anonymized and encrypted, such as while connected to a VPN and connected to the Tor anonymity network.
This AI works because it inspects the browsed, not the one browsing. The advertisement is then not just targeted, but it’s contextually relevant. It’ll even tell you the general color palette of the website before choosing visual assets for the ad display. As the zveloAPI (used to access zveloDP’s AI services and data) becomes more widely adopted, we expect it to be a no-brainer implementation for ad platforms. It’s a very low-risk way to provide high-quality ad placement logic in a non-invasive way.
Q: You mention “hard” and “soft” entities on the web, what’s the difference?
A hard entity is an internet-enabled device in the Internet of Things (IoT), a server, or any other piece of connected infrastructure, physical or virtualized. It’s levels 1-4 of the OSI networking model; Physical through Transport. Soft entities are software constructs; instanced logic in the datasphere. Running applications, atoms of data. It’s roughly levels 5-7. This distinction is English syntactic sugar, and is actually a spectrum, not a flag.
Q: Can you tell us a little about the zvelo development team?
Our team consists of people adept in AI Research, Computer Science, Software Engineering, Big Data, Security, and Cloud Infrastructure. This has truly been a multi-disciplinary endeavor. We are very excited about the release of zveloDP because it is the culmination of years of work bringing theoretical multi-agent AI algorithms to the market in the form of a clear API, and it required we all step outside popular distinctions.
This effort has been a theoretical AI and practical engineering challenge. Our team is tooled to ensure these theories meet practice in the form of a service for use by the wider web.
Q: Is this zvelo’s first “Cloud”-based offering?
We’ve been a pioneer in Cloud services for a long time and have considerable intellectual property and patents related to cloud computing, particularly in the area of managing subscriptions to cloud-based services. With the zveloDP, we are moving beyond the Cloud to more of a hybrid, or what is being called “fog computing,” where you keep the data and services in the most cost-effective and processing efficient locations, such as cloud, local or intermediaries.
Q: What makes the zveloDP and Cloud API unique?
Deploying the zveloDP through a Cloud API for direct integration finally makes these advanced AI systems available for use in any scale network, device, or app at pricing levels that provide zero impedance to early adoption. We’re excited to be among the first to provide access to AI as a Service. Being a “Cloud” company means we are handling the nontrivial task of running this service at scale, globally available, as a metered utility.
Q: To bring this service live, you’ve had to leverage some cutting-edge tech. Why is that?
Our categorization and detection AI engine is based on the work of Dr. Ignacio Giraldez, Universidad Carlos III de Madrid, in Multi-Agent-Systems (MAS). Dr. Giraldez is currently running our AI Research group, and we’re thrilled to see his algorithms applied. The general idea is to use a distributed approach to learning, with multiple trained detectors (agents) in deployment. This method yields exceptionally high accuracy and algorithmic efficiency, as well as reasonable algorithmic complexity and surprisingly short latency. However, the resources required to do thousands of simultaneous AI detections for every request presents a non-trivial engineering challenge.
The algorithm may be of reasonable complexity, but the constant modifier is significant. One of the reasons we don’t see these systems in the marketplace already is a very practical limitation of the sheer computing horsepower required at scale. To solve this, we’ve had to use some of the latest innovations from the Cloud space.
Q: Let’s talk shop. What’s the stack?
I prefer a top-down answer to this question if that’s ok. Our API is available globally of course, but responsiveness is a big consideration. We use latency-based routing to ensure a user always reaches the fastest AI deployment. All our services are written natively in Google’s Go (golang). The language’s design goals, structure and primitives (in particular channels) are a perfect fit for our AI’s distributed computational nature, and we are continuing to be more involved in the growing Go community as a result.
We have implemented the entire platform using a Service-oriented Architecture (SoA) where the overall system is comprised of many sub-component internal network services, each with a variable number of instances that scales according to load. These interconnected black boxes exist in a flat network space. This works very well, but it presents a practical problem of scaling services and fault-tolerance across a nontrivial number of processes and servers. We’ve therefore deployed the Kubernetes container manager, which makes a large number of cluster components manageable.
We use continuous integration services that auto-deploy updated binaries in very short cycles, keeping us agile, able to evolve the AI quickly with no downtime and newly trained models can go from AI Research to Production in minutes.
Interprocess communication is handled using a combination of GRPC (remote procedure calls using Google Protocol Buffers) and NSQ (a distributed messaging service developed at Bit.ly). We’ve put the special sauce into abstractions on these base message passing systems, including the ability to create cluster-level distributed transactions using high-level APIs. This is then coupled with the high-speed data-structure store Redis to function as cluster-level RAM. The system is scalable and quite tolerant of hardware failures, network instability, and variable load levels. The highly distributed nature of each computation keeps end-to-end latency low. Finally, the nodes in our cluster are running CoreOS, a Linux operating system specially designed for containerized cluster deployments such as ours.
Q: When you say “Highly Distributed”, what makes this system “more distributed” than a typical cluster?
In most clustered environments, requests are distributed. In our cluster, this is also true, but in addition, the request algorithm execution work unit itself is being distributed. Thus I felt the qualifier appropriate.
If you remember distributed computation systems such as GIMPS (1996) or SETI@Home (1999), these systems took a large unit of work and split it up into constituent, parallelizable work atoms and sent them to multiple computers for processing. This is the general method that we use internally to the cluster, where the arduous task of multi-classification is processed in parallel across many nodes, many processes on those nodes, and concurrently within those processes as goroutines. It’s a bit like neurons, firing together, but learning does not take place in production because there’s no back-weighting or information feedback in that context.
Q: Is this system really an “artificial intelligence”?
Not in the way we colloquially define “intelligent”. This is a Special Intelligence (SI), specializing in multiple ways of detecting patterns in data. The system is a platform for the creation and deployment of arbitrary future detector types and data. It’s intelligence, yes, but wholly specialized. What that means is it’s more like a sense organ plus that organ’s associated data processing in the brain than it is a desire-based goal-seeking intelligence. Think collective human sensory augmentation, not Strong AI.
Q: So, the big question everyone wants to know is, will it become aware and destroy the humans?
In a word? No.
About the Author
Luke Kingland brings 17 years of experience engineering Internet-based services for the energy, security, and education industries. As a Full Stack Engineer, Luke leverages deep knowledge of the full software stack used in modern software development to bring cohesion and clarity to the overall solution.





